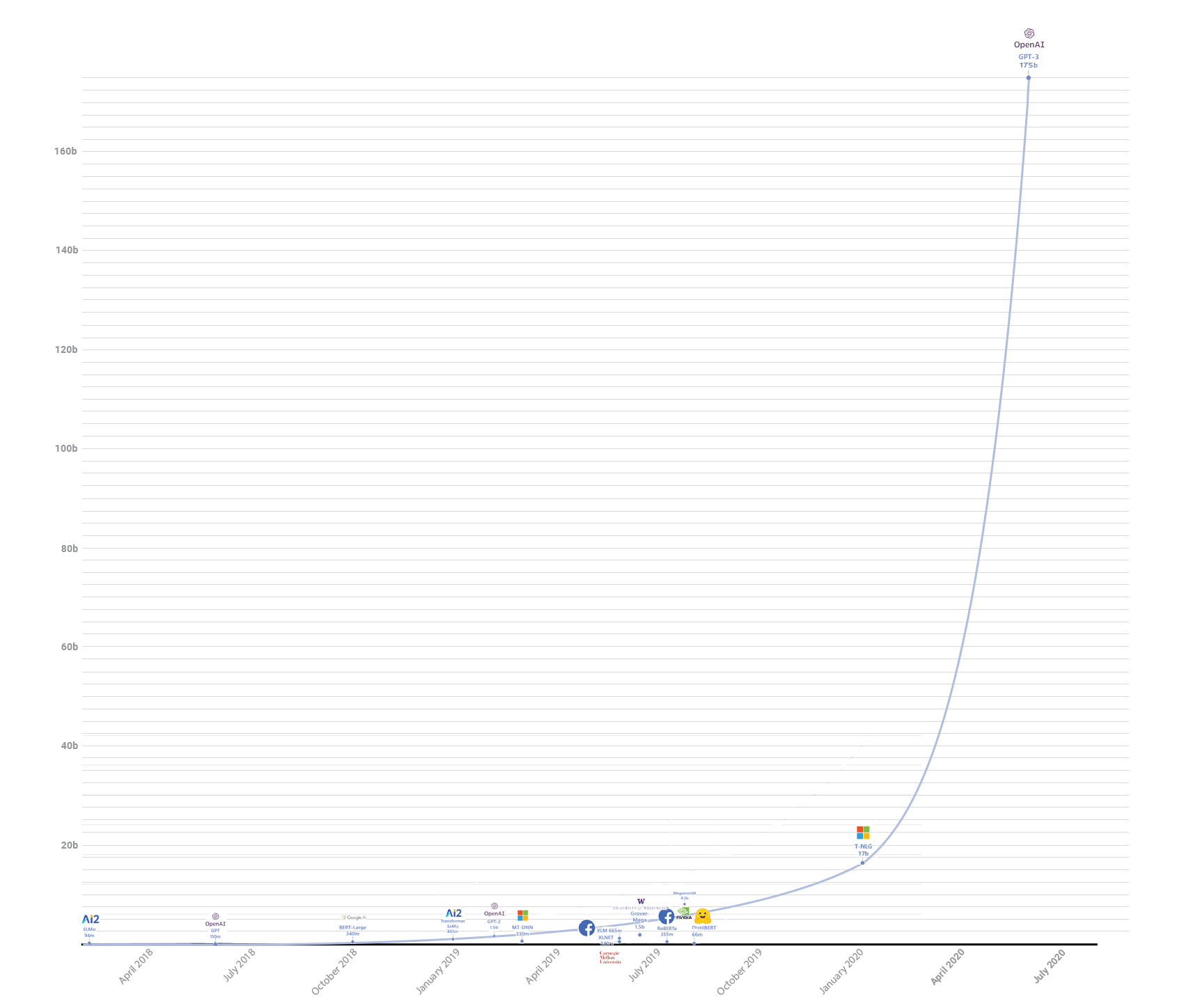
 Number of Parameters of GPT-3 compared to previous models. (Edited by WillStats, Original 1, Original 2)
Number of Parameters of GPT-3 compared to previous models. (Edited by WillStats, Original 1, Original 2)
The sheer scale of the new GPT-3 model is hard to overstate; it’s an entire order of magnitude larger than Microsoft’s already-massive 17B parameter Turing-NLG.[1] Loading the entire model’s weights in fp16 would take up an absolutely preposterous 300GB of VRAM, not even including the gradients. But, with massive size comes massive generalization ability: GPT-3 is competitive in many benchmarks without even tuning on the target task. And when I say many, I mean many—the full, 72-page paper contains an extensive evaluation of GPT-3 on many NLP datasets. Through the OpenAI API, a vast array of impressive demos have sprung up taking advantage of the generalization capabilities of GPT-3 to do extremely disparate tasks. Perhaps the most impressive part, though, is that even at such a massive scale, the model still scales smoothly in performance instead of plateauing, implying that still-larger models would perform even better. Throughout the rest of this post, my goal is to distill this massive (in multiple ways) paper down to a digestible size, and shed some light on why it matters.
Model
The following table summarizes some of the largest autoregressive Transformer models of the past few years. I’ve excluded models like XLNet and BERT-derivatives because they don’t have the same unidirectional autoregressive training target.
| Parameters | Layers | Hidden Size | Attn Heads | Attn Head Dimension | Context Length | |
|---|---|---|---|---|---|---|
| GPT | 0.110B | 12 | 768 | 12 | 64 | 512 |
| GPT-2 | 1.542B | 48 | 1600 | 25 | 64 | 1024 |
| Megatron-LM | 8.3B | 72 | 3072 | 32 | 96 | 1024 |
| Turing-NLG | 17B | 78 | 4256 | 28 | 152 | 1024 |
| GPT-3 | 175.0B | 96 | 12288 | 96 | 128 | 2048 |
While GPT-3 isn’t that much deeper, its width is nearly 3x that of Turing-NLG, which—since parameter count scales approximately proportional to the square of the hidden size—explains where most of the extra parameters come from. It also has double the context size, at 2048 tokens, which is impressive (and memory-expensive!), though not the biggest context size across all models; some models have even longer contexts, like Transformer-XL, which incorporates longer contexts by passing context vectors between segments, and Reformer, which uses locality-sensitive hashing to enable sparser attention. Similarly, GPT-3 uses sparse attention layers in every other layer, though the exact details are left somewhat ambiguous. It’s also interesting to note that the smaller GPT-3 versions trained for comparison with GPT-2 are slightly shallower and wider, with GPT-3-XL having only 24 layers but a hidden size of 2048.[2] GPT-3 also reuses the BPE tokenization of GPT-2. Overall, GPT-3 is essentially just a downright massive version of GPT-2.
Training Data
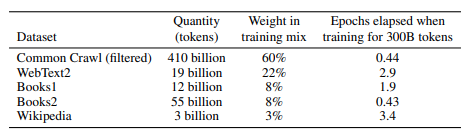 Weighted Training Data (Source)
Weighted Training Data (Source)
The training data is a reweighted mix of Common Crawl, WebText2 (a larger version of the original that also includes links sampled in the period of Jan-Oct 2018), two book corpora, and English Wikipedia. Some of these components, such as Wikipedia, were seen more than 3 times during training; others, like the massive Common Crawl component, had less than half of their data seen. The authors claim that this is to help raise the overall quality of the corpus by prioritising known-good datasets. Also, in contrast to the original WebText, this new corpus is not filtered by language, but English still constitutes 93% of the dataset by words simply due to its prevalence. Altogether, the dataset is 500 billion tokens, or 700GB[3], after filtering and cleaning. The paper also provides a detailed description of the filtering process of the dataset, which the GPT-2 paper didn’t.
The authors also attempted to remove any data that overlapped with the train and test sets of the evaluations. Unfortunately, due to a bug, some were missed, so to compensate the paper provides a fairly good analysis of the impact of this leakage.
Evaluation
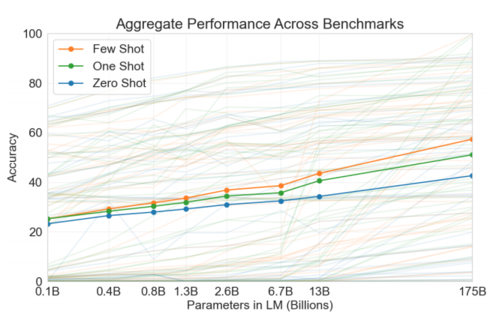 Zero-, One-, and Few-shot performance of GPT-3 scaling with parameter count (Source)
Zero-, One-, and Few-shot performance of GPT-3 scaling with parameter count (Source)
The Evaluation section of GPT-3 is very comprehensive, evaluating on a massive battery of NLP tasks in the Zero-shot (given only a natural language description in the generation context), One-shot (a single example in the generation context), or Few-shot (a small handful of examples in the generation context) settings. This setting is worth emphasizing as perhaps one of the biggest differences in ability between GPT-2 and its predecessors, because being able to infer the task from just one or a few examples is a massive step forward in generalization. Whereas previous models all relied on task-specific tuning, GPT-3 can be “tuned” merely by giving it instructions in plain English! In fact, the paper doesn’t even attempt to fine-tune on the target task, leaving that to future work.[4] However, one crucial conclusion is that in almost all tests, performance continues to get better with larger models, even across 4 entire orders of magnitude, whereas fine-tuning only improves on one task and risks catastrophic forgetting and overfitting.
Without going too much into the individual tests, the general result is this: on most tasks, GPT-3 achieves performance significantly worse than fine-tuned SOTA (i.e SuperGLUE, CoQA, Winograd, to name a few), but beating fine-tuned SOTA for some other tasks (i.e PhysicalQA, LAMBADA, Penn Tree Bank). GPT-3 does particularly well on PTB in particular, taking the SOTA perplexity from 35.76 down to 20.5—a massive improvement. GPT-3 can also finally do some arithmetic, something GPT-2 was unable to do well.[5]
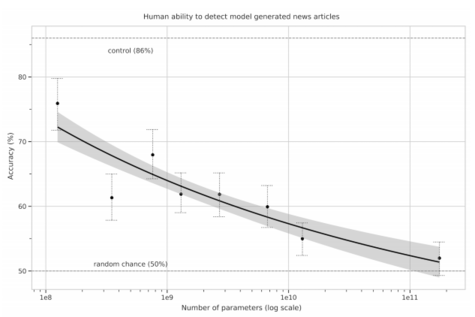 People are unable to separate GPT-3 generated news articles from real ones (Source)
People are unable to separate GPT-3 generated news articles from real ones (Source)
Impressively, and perhaps somewhat alarmingly, people are unable to distinguish GPT-3 generated news stories from real ones, only exacerbating the ethical concerns already raised by GPT-2. The paper analyzes the result of the release of GPT-2, and concludes that the release of GPT-2 has not led to widespread use of LMs for misinformation due to the difficulty of controlling output and variance in output quality, both among low-to-mid skill adversaries and “advanced persistent threats”—adversaries with “high skill and long-term agendas”—such as state actors. However, the paper also acknowledges that with further development, LMs will eventually become advanced enough for these adversaries.
The authors also investigate gender bias in GPT-3, showing that GPT-3 is male leaning; however, the authors claim that some preliminary evidence on the Winogender dataset (which tests coreference resolution on the same sentence but with different gendered pronoun) seems to suggest that larger models are more robust to bias issues. Similar issues appeared for race and religion, with the sentiment of coöccurrent terms varying significantly with race. The authors claim that this issue also got better with the larger models—although, without proper hypothesis testing, it’s difficult to draw any solid conclusions here.
Downstream Applications
GPT-3 has already been used for a smorgasbord of different applications through the OpenAI API. You can ask it to write code, turn natural language commands into shell commands, and simulate chatting with famous people. You can ask it to answer medical questions, or write parodies of the navy seal copypasta. You can ask it to summarize passages for second graders, or write poetry.
It’s important to remember all these are done by the exact same model trained only on modelling text; all that’s different is that it has been “asked nicely” to do different things. These apps showcase the versatility of GPT-3 across many disparate domains—something that, if it were done with GPT-2, would require days or even weeks of extensive data engineering and fine tuning, rather than 15 minutes of prompt crafting. This new paradigm of programming through crafting plain-English prompts, jokingly dubbed “Software 3.0”, has achieved results that are already impressive, but even more impressive when viewed through the lens of generalization; GPT-3 wasn’t trained to do any of these things in particular, but it could still be asked[6] to do them, and fairly well at that!
Conclusion
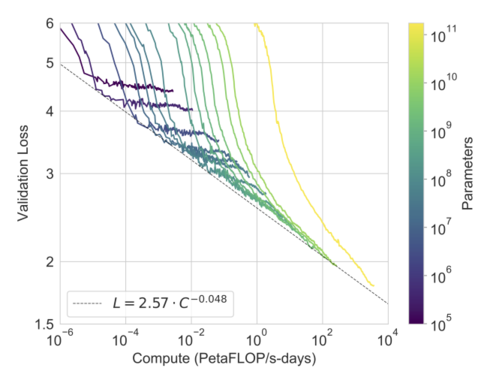 Performance continues to scale with compute. (Source)
Performance continues to scale with compute. (Source)
But why does GPT-3 matter, if it can’t even beat SOTA across all benchmarks? Why should we care about a model so large that a small computing cluster is necessary even just to run inference at a reasonable speed?
One thing about GPT-3 is that it’s doing reasonably well on tasks it has never even seen, and sometimes tasks not even anticipated by the developers of the model. Additionally, instead of reaching a point of diminishing returns, GPT-3 shows that the trend of larger models performing better continues for at least another order of magnitude, with no signs of stopping. Even though GPT-3 is unwieldy, and even though it still doesn’t quite reach human level performance across the board, GPT-3 shows that it’s possible for a model to someday reach human levels of generalization in NLP—and once the impossible becomes possible, it’s only a matter of time until it becomes practical.
Back when I talked about large Transformer language models like GPT-2, CTRL, and Megatron-LM late last year, I touched briefly on the trend of Language Models getting bigger, and covered some of the issues that simply more compute might not fix. My general anticipation was that the model size arms race would soon be at a temporary standstill, with focus being diverted to better decoding strategies for text generation (perhaps via RL-based methods). I most certainly had not expected that OpenAI would be back at it so soon with such a massive model.
This was such a surprise that I dropped everything to read the paper and work on this post, including a more theory-oriented post that I’ve been working on for a few months now. It will probably be finished soon™, after I recover from GPT-3 shock. Stay tuned! ↩︎
It’s likely that this was done for easier model parallelism—bigger matrix multiplications are much easier to parallelize than sequentially-applied layers à la GPipe.
This could have other advantages too, though. After EfficientNet came out, I independently ran some experiments of the same concepts to Transformer models, and the result was that for the same amount of compute, wider models had a sizeable advantage over deeper ones—which corroborates the choice here to go with wider models. ↩︎
This figure is extrapolated from the size of the Common Crawl set, which is given in the paper. ↩︎
There has been some speculation over the lack of fine-tuning examples in this paper. Some have speculated that the fine-tuned performance is poor, leading OpenAI to exclude the results. It could be that with a model this big, the fine tuning paradigm starts to break down due to the ease of overfitting, though without access to the model (and hardware to tune it!) there’s not much more than speculate that we can do.
An update: OpenAI has talked about releasing a fine-tuning API. It remains to be seen exactly how the API will work, but I’m personally excited to see the results on various datasets. There has been debate over whether fine-tuning GPT-3 would actually result in performance gains, and seeing the result either way would be very informative. ↩︎
There is some evidence that the Byte-Pair Encoding used in GPT3 may be the source of many issues, especially surrounding arithmetic and rhyming. BPE glues together adjacent characters which creates difficulties for the model when those characters are individually semantically meaningful. ↩︎
The word “ask” is often abused to refer to getting models to do things in general, but in this case we’re literally asking the model! ↩︎