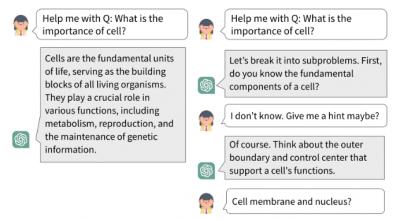
This article raises the issue of 'pedagogical alignment' of large language models. What does 'pedagogical alignment' even mean in this context? It "involves breaking complex problems into manageable steps and providing hints and scaffolded guidance rather than direct answers." That strikes me as very narrow, but let's persist. The authors "propose a novel approach to achieve pedagogical alignment by modeling it as learning from human preferences (LHP)... to represent desired teaching behaviors as preferences, enabling more nuanced optimization." And this (of course) requires data "to quantitatively measure an LLM's tendency to provide step-by-step guidance versus direct answers, offering a robust metric for pedagogical alignment." And so plays out the paper. I would find such an AI very frustrating. I think we need a model of learning that is something that isn't spoonfeeding.
Today: 0 Total: 414 [] [Share]



{kind=link}