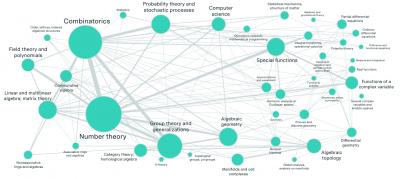
According to this article, "60 mathematicians from leading institutions worldwide (have) introduced FrontierMath, a new benchmark designed to evaluate AI systems' capabilities in advanced mathematical reasoning." Basically it's a set of mathematical problems drawing from such bodies of knowledge as number theory, probability and geometry to be posed to AI systems to test their mathematical skills. It's a tough test; current large language models score in the 2% range (not a typo: that's two percent). What I wonder is how well humans would perform on the same test. Now obviously, mathematicians who have had a lot of experience and practice would do well. Me? Well I would have to brush up. A lot.
Today: 0 Total: 468 [] [Share]



{kind=link}