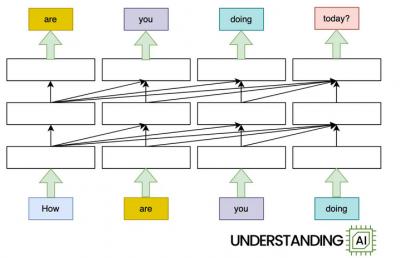
If you've done any amount of work with a large language model, you will have encountered this problem: transformer-based models like ChatGPT get less efficient as you give them more and more content to consider. In short, "transformers have a scaling problem." This article considers this problem. It describes "FlashAttention," which "calculates attention in a way that minimizes the number of these slow memory operations." It also mentions "scaling attention across multiple GPUs." It also considers a Google hybrid between a transformer and a Recurrent Neural Network (RNN) and Mamba, another RNN project. But it's an open issue because "we want models that can handle billions of tokens" without forgetting them.
Today: 0 Total: 819 [] [Share]



{kind=link}